请详细解释Python代码的执行过程 #
包括编译、解释、运行的具体步骤
Python代码的执行过程是一个多层次的处理流程,主要可以分为编译、解释、运行三个阶段。
1. Python代码执行的基本流程 #
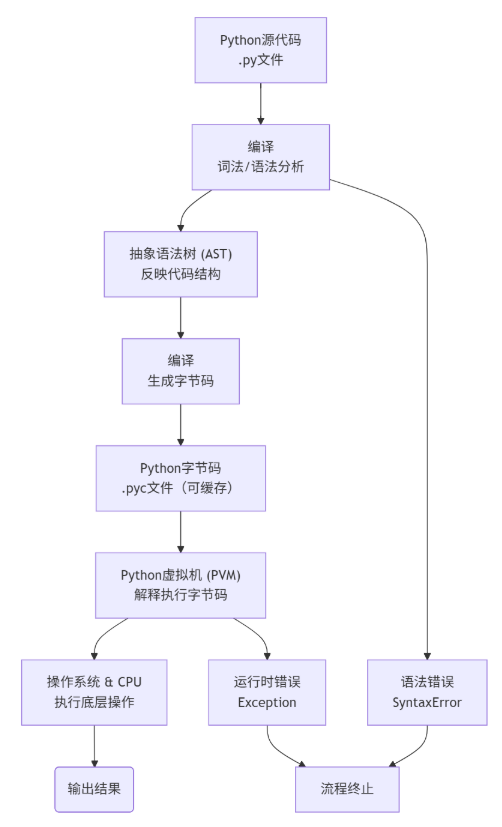
(1)源代码(Source Code)
Python开发者编写的 .py 文件,通常是人类可读、易于理解的文本格式代码。
(2)编译为抽象语法树(AST) 执行前,Python解释器首先对源代码进行语法分析,将其转换为一棵抽象语法树(AST)。AST反映了代码的结构和语义层次,便于后续处理。
(3)编译为字节码(Bytecode) AST会被进一步编译为Python虚拟机(CPython)的字节码,这是一种面向栈的中间代码,接近底层但仍跨平台。字节码不是机器码,而是Python虚拟机可执行的指令序列。
(4)解释执行(Interpretation/Execution) Python虚拟机逐条读取、解释字节码,并触发实际的运算或系统调用。最终程序在操作系统上运行,得到输出结果。
流程简要总结
- 源代码 → 人类编写的
.py脚本 - 词法/语法分析 → 转为AST
- 编译 → 生成字节码(
.pyc文件可能被缓存) - 解释执行 → 由虚拟机逐条执行字节码
- 输出结果 → 显示/写文件等
这样做的好处是,Python跨平台、开发快,并且支持即时执行和代码热更新等特性。
2. 编译阶段 #
2.1 编译过程 #
编译阶段主要包括:词法/语法分析(生成抽象语法树AST)和字节码生成
# 导入 ast 模块,用于处理抽象语法树
import ast
# 导入 dis 模块,用于反汇编字节码
import dis
# 定义一段源代码,内容为:a=1 和 print(a)
source_code = '''
a=1
print(a+2)
'''
print("1. 源代码:")
# 打印上面定义的源代码
print(source_code)
print("2. 抽象语法树(AST):")
try:
# 调用 ast.parse 解析源代码为 AST 对象
tree = ast.parse(source_code)
# 用 ast.dump 打印整个 AST 结构,并设置缩进为2
print(ast.dump(tree, indent=2))
except SyntaxError as e:
# 如果解析过程中抛出语法错误,打印相应信息
print(f"语法错误: {e}")
print("\n3. 字节码:")
try:
# 使用 compile 函数将源代码编译为字节码对象,文件名设置为 <string>,模式为 exec
code_obj = compile(source_code, '<string>', 'exec')
# 打印刚才获得的字节码对象的信息
print(code_obj)
# 调用 dis.dis 反汇编字节码,输出详细的字节码指令列表
dis.dis(code_obj)
except SyntaxError as e:
# 如果编译源代码时出现语法错误,打印提示信息
print(f"编译错误: {e}")
print("\n4. 执行结果:")
try:
# 用 exec 执行上面 compile 出来的字节码对象
exec(code_obj)
except Exception as e:
# 如果在执行过程中抛出异常,打印错误提示
print(f"执行错误: {e}")1. 源代码:
a=1
print(a+2)
2. 抽象语法树(AST):
Module( # 模块节点
body=[
Assign( # 赋值语句
targets=[
Name(id='a', ctx=Store())], # 变量a,作为赋值目标
value=Constant(value=1)), # 常量1,赋值给a
Expr( # 表达式(单独一行的表达式作为语句出现)
value=Call( # 函数调用
func=Name(id='print', ctx=Load()), # 调用print函数
args=[
BinOp( # 二元运算表达式
left=Name(id='a', ctx=Load()), # 左操作数为a
op=Add(), # 运算符为加法
right=Constant(value=2))]))]) # 右操作数为常量2
3. 字节码:
<code object <module> at 0x00000148FA752D30, file "<string>", line 1>
0 RESUME 0 # 开始执行字节码
2 LOAD_SMALL_INT 1 # 加载整数1
STORE_NAME 0 (a) # 将1赋值给变量a
3 LOAD_NAME 1 (print) # 加载print函数
PUSH_NULL # 为CALL指令做准备,填充NULL
LOAD_NAME 0 (a) # 加载变量a的值
LOAD_SMALL_INT 2 # 加载整数2
BINARY_OP 0 (+) # 执行a+2加法运算
CALL 1 # 调用print函数,传递一个参数
POP_TOP # 弹出print返回值
LOAD_CONST 1 (None) # 加载None,作为返回值
RETURN_VALUE # 返回(结束模块执行)
4. 执行结果:
32.2 .字节码缓存机制 #
当我们运行 Python 脚本(例如 python example.py)时,执行过程并不仅仅是简单的“从源码到结果”,而是涉及多个中间步骤。字节码缓存机制是其中的重要一环,它提升了 Python 代码的执行效率。下面详细解释其工作流程:
3.1 字节码与缓存的概念 #
- 字节码(Bytecode):是 Python 源代码经过编译后生成的一种中间表示形式。它和具体平台无关,由 Python 解释器(CPython)进一步解释执行。
- 缓存机制:为了避免每次都从头编译源文件,Python 会将编译产生的字节码缓存为
.pyc文件,通常存放在__pycache__目录下。下次运行时,如果源码无变化,Python 会直接加载缓存的字节码,大大加快启动速度。
3.2 缓存机制的具体步骤 #
第一次运行
当你第一次运行某example.py文件时,Python 会:- 先将
.py源码编译成字节码。 - 再执行字节码。
- 并将字节码以
.pyc文件形式缓存到__pycache__目录。缓存文件名一般包含 Python 版本(如:example.cpython-311.pyc)。
- 先将
后续运行
再次运行时,Python 会:- 检查
__pycache__下是否有对应.pyc缓存,且缓存是“新鲜的”(即源文件没被修改过)。 - 如缓存有效,直接加载
.pyc文件并执行,跳过源码编译步骤,启动更快。 - 如源码已更改,缓存失效,重新编译生成新的
.pyc文件。
- 检查
3. 解释阶段 #
在这一阶段,Python 虚拟机(PVM, Python Virtual Machine)会读取字节码,并将其逐条“解释”成底层计算机操作,由操作系统和硬件最终完成运算。此步骤不涉及重新编译,仅依赖字节码本身。PVM 的主要任务:
- 按顺序执行字节码中的每一条指令
- 处理变量赋值、函数调用、表达式计算等操作
- 动态管理内存(如对象的创建和销毁)
- 处理异常和其他运行时机制
3.1 执行步骤 #
- 加载字节码
- Python 解释器将上一步编译得到的字节码载入内存。
- 执行循环(Eval Loop)
- PVM 进入主循环,每次取出下一条字节码指令,识别操作类型(如计算、赋值、跳转、异常处理等)。
- 解释与调度
- 对每条指令做相应的操作,比如计算表达式、调用函数、跳转分支、操作内存和堆栈等。
- 输出与结束
- 按需向终端/文件输出结果,所有代码执行完毕则 PVM 退出,结束本次运行。
PVM 并不是物理机器,而是通过软件方式实现的“虚拟”处理器。它让同一个 Python 字节码能够在不同平台(Windows、macOS、Linux 等)上顺利运行,这也是 Python 跨平台能力的重要基础。
Python 解释器最后这一步,就是靠虚拟机一条条把字节码‘翻译’成计算机能执行的操作,像逐条走流程一样执行程序。这既保证了代码的可移植性,又能动态地处理各种运行时细节。
3.2 指令执行代码 #
# 定义一个简单的虚拟机类
class SimpleVM:
"""Python虚拟机"""
# 初始化方法
def __init__(self):
# 初始化操作数栈
self.stack = [] # 操作数栈 - 存储计算过程中的临时数据
# 初始化局部变量字典
self.locals = {} # 局部变量 - 存储函数内的变量
# 初始化全局变量字典
self.globals = {} # 全局变量 - 存储全局变量
# 加载常量到操作数栈顶 把数字、字符串等常量放到栈顶
# load_const(10) 会把数字10放到栈里
def load_const(self, const):
# 将常量值加入到栈顶
self.stack.append(const)
# 输出调试信息
print(f"加载常量: {const} -> 栈: {self.stack}")
# 加载变量的值到操作数栈顶 根据变量名找到对应的值,然后放到栈顶
# load_name('a') 会找到变量a的值,放到栈里
def load_name(self, name):
# 如果变量在局部变量字典中
if name in self.locals:
value = self.locals[name]
# 如果变量在全局变量字典中
elif name in self.globals:
value = self.globals[name]
# 变量不存在,则抛出异常
else:
raise NameError(f"name '{name}' is not defined")
# 将变量值加入到栈顶
self.stack.append(value)
# 输出调试信息
print(f"加载变量: {name} = {value} -> 栈: {self.stack}")
# 将操作数栈顶的值存储到指定变量 把栈顶的值取出来,存储到指定的变量中
# store_name('a') 会把栈顶的值存到变量a中
def store_name(self, name):
# 如果栈为空,则抛出异常
if not self.stack:
raise RuntimeError("栈为空")
# 取出栈顶值
value = self.stack.pop()
# 存储到局部变量字典中
self.locals[name] = value
# 输出调试信息
print(f"存储变量: {name} = {value}")
# 执行加法操作 从栈顶取出两个数,相加后把结果放回栈顶
# 栈里有[10, 20],执行后变成[30]
def binary_add(self):
# 检查操作数栈中是否有2个及以上元素
if len(self.stack) < 2:
raise RuntimeError("栈中元素不足")
# 弹出右操作数
b = self.stack.pop()
# 弹出左操作数
a = self.stack.pop()
# 执行加法计算结果
result = a + b
# 结果压栈
self.stack.append(result)
# 输出调试信息
print(f"加法: {a} + {b} = {result} -> 栈: {self.stack}")
# 返回操作数栈顶的值 从栈顶取出值并返回
def return_value(self):
# 如果栈为空,返回None
if not self.stack:
return None
# 弹出并返回栈顶值
value = self.stack.pop()
# 输出调试信息
print(f"返回: {value}")
return value
# 演示虚拟机指令执行过程的函数
def vm_execution():
# 创建虚拟机实例
vm = SimpleVM()
# 输出即将执行的代码说明
print("执行代码: a = 10; b = 20; c = a + b")
# 构造指令序列
instructions = [
('LOAD_CONST', 10), # 加载常量10
('STORE_NAME', 'a'), # 存储到变量a
('LOAD_CONST', 20), # 加载常量20
('STORE_NAME', 'b'), # 存储到变量b
('LOAD_NAME', 'a'), # 加载变量a
('LOAD_NAME', 'b'), # 加载变量b
('BINARY_ADD',), # 执行加法
('STORE_NAME', 'c'), # 存储到变量c
('LOAD_NAME', 'c'), # 加载变量c
('RETURN_VALUE',), # 返回值
]
# 依次执行指令
for instruction in instructions:
# 取操作码
op = instruction[0]
# 取操作数参数
args = instruction[1:] if len(instruction) > 1 else []
# 根据操作码分发指令
if op == 'LOAD_CONST':
vm.load_const(args[0])
elif op == 'STORE_NAME':
vm.store_name(args[0])
elif op == 'LOAD_NAME':
vm.load_name(args[0])
elif op == 'BINARY_ADD':
vm.binary_add()
elif op == 'RETURN_VALUE':
result = vm.return_value()
# 返回值后跳出循环
break
# 输出最终结果
print(f"\n最终结果: c = {result}")
# 执行虚拟机演示
vm_execution()3.3 执行过程 #
3.3.1 要执行的代码 #
a = 10
b = 20
c = a + b3.3.2 对应的指令序列 #
instructions = [
('LOAD_CONST', 10), # 1. 把10放到栈里
('STORE_NAME', 'a'), # 2. 把栈顶的10存到变量a
('LOAD_CONST', 20), # 3. 把20放到栈里
('STORE_NAME', 'b'), # 4. 把栈顶的20存到变量b
('LOAD_NAME', 'a'), # 5. 把变量a的值(10)放到栈里
('LOAD_NAME', 'b'), # 6. 把变量b的值(20)放到栈里
('BINARY_ADD',), # 7. 把栈顶两个数相加(10+20=30)
('STORE_NAME', 'c'), # 8. 把结果30存到变量c
('LOAD_NAME', 'c'), # 9. 把变量c的值(30)放到栈里
('RETURN_VALUE',), # 10. 返回栈顶的值(30)
]3.3.3 执行过程 #
步骤1-2: a = 10
LOAD_CONST 10 → 栈: [10]
STORE_NAME 'a' → 变量a = 10, 栈: []步骤3-4: b = 20
LOAD_CONST 20 → 栈: [20]
STORE_NAME 'b' → 变量b = 20, 栈: []步骤5-6: 准备加法
LOAD_NAME 'a' → 栈: [10]
LOAD_NAME 'b' → 栈: [10, 20]步骤7: a + b
BINARY_ADD → 栈: [30] (10 + 20 = 30)步骤8: c = a + b
STORE_NAME 'c' → 变量c = 30, 栈: []步骤9-10: 返回结果
LOAD_NAME 'c' → 栈: [30]
RETURN_VALUE → 返回303.3.4 核心概念 #
3.3.4.1 栈 #
- 想象一摞盘子,只能从顶部放和取
- 后放进去的先取出来(后进先出)
- 用于临时存储计算过程中的数据
3.3.4.2 变量存储 #
- 变量名和值的对应关系存储在字典中
- 局部变量和全局变量分开存储
- 查找变量时先找局部,再找全局
3.3.4.3 指令执行 #
- 每个操作对应一个指令
- 指令有操作码(做什么)和操作数(对什么做)
- 按顺序执行指令序列
3.3.4.4 实际运行效果 #
加载常量: 10 -> 栈: [10]
存储变量: a = 10
加载常量: 20 -> 栈: [20]
存储变量: b = 20
加载变量: a = 10 -> 栈: [10]
加载变量: b = 20 -> 栈: [10, 20]
加法: 10 + 20 = 30 -> 栈: [30]
存储变量: c = 30
加载变量: c = 30 -> 栈: [30]
返回: 30
最终结果: c = 304. 参考回答 #
4.1 开场白(20秒) #
Python代码的执行过程主要分为三个阶段:编译、解释、运行。虽然Python被称为解释型语言,但实际上它也有编译过程。
4.2 核心流程(60秒) #
"具体来说,执行过程是这样的:
第一步,编译阶段:
- 源代码先经过词法分析和语法分析,生成抽象语法树(AST)
- AST再被编译成字节码,这是一种中间代码,不是机器码
- 字节码会被缓存为
.pyc文件,下次运行相同代码时直接加载,提高效率
第二步,解释阶段:
- Python虚拟机(PVM)逐条读取字节码指令
- 每条指令对应一个具体操作,比如加载变量、执行运算、函数调用等
- 虚拟机维护一个操作数栈来存储计算过程中的临时数据
第三步,运行阶段:
- 虚拟机将字节码指令转换为实际的系统调用和硬件操作
- 最终在操作系统上执行,产生输出结果"
4.3 关键特点(30秒) #
"Python执行过程有几个重要特点:
跨平台性:字节码是平台无关的,同一份代码可以在不同操作系统上运行
动态性:运行时可以动态创建对象、修改变量,支持反射等特性
缓存机制:.pyc文件缓存大大提高了重复执行的启动速度
虚拟机架构:通过虚拟机抽象了底层硬件差异,保证了代码的可移植性"
4.4 举例说明(30秒) #
"举个简单例子,a = 10; b = 20; c = a + b这段代码:
- 编译后变成字节码指令序列
- 虚拟机执行:加载常量10→存储到a→加载常量20→存储到b→加载a和b→执行加法→存储结果到c
- 整个过程通过操作数栈来管理数据,最终得到c=30的结果"
4.5 结尾(10秒) #
总的来说,Python虽然是解释型语言,但通过编译成字节码和虚拟机执行的方式,既保证了跨平台性,又提供了良好的性能。
4.6 回答技巧提示 #
- 控制时间:总时长控制在2-3分钟
- 层次清晰:按照编译→解释→运行的顺序展开
- 突出特点:强调跨平台、动态性、缓存机制
- 准备深入:如果面试官追问,可以详细解释字节码指令或虚拟机原理
- 结合实际:可以提到自己使用Python时观察到的
.pyc文件或性能优化经验