1. Unicode 转 UTF-8 #
1.1 Unicode 是什么? #
Unicode 是一个字符集标准,为世界上几乎所有的字符分配了一个唯一的编号,称为码点(Code Point)。
- 表示方式:
U+xxxx(十六进制) - 例如:
'A'=U+0041= 65(十进制)'中'=U+4E2D= 20013(十进制)'😀'=U+1F600= 128512(十进制)
1.2 UTF-8 是什么? #
UTF-8 是 Unicode 的一种编码方式,将 Unicode 码点转换为字节序列,用于存储和传输。
1.3 为什么需要 UTF-8? #
- Unicode 只定义了字符的编号,但没有规定如何在计算机中存储
- UTF-8 是最流行的 Unicode 编码方式
- 特点:
- 变长编码(1-4字节)
- 兼容 ASCII(ASCII字符只用1字节)
- 节省空间
2. UTF-8 编码规则 #
2.1 编码规则表 #
| Unicode 范围 | 十进制范围 | 字节数 | UTF-8 编码格式 | 数据位数 |
|---|---|---|---|---|
U+0000 ~ U+007F |
0 ~ 127 | 1字节 | 0xxxxxxx |
7位 |
U+0080 ~ U+07FF |
128 ~ 2047 | 2字节 | 110xxxxx 10xxxxxx |
11位 |
U+0800 ~ U+FFFF |
2048 ~ 65535 | 3字节 | 1110xxxx 10xxxxxx 10xxxxxx |
16位 |
U+10000 ~ U+10FFFF |
65536 ~ 1114111 | 4字节 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
21位 |
通常,在计算机领域里,FF 是十六进制表示法,写作 0xFF。
十六进制中:
F代表十进制的 15- 每一位的权值是 16 的幂。
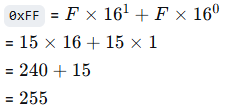
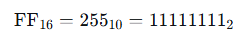
在十六进制中:
F代表十进制的157F可以看作是7 * 16 + 15,所以7 * 16 + 15 = 112 + 15 = 12707FF可以看作是 0x07FF = 7 × 16² + 15 × 16 + 15 = 1792 + 240 + 15 = 2047FFFF可以看作是 0xFFFF = 15 × 16³ + 15 × 16² + 15 × 16 + 15 = 61440 + 3840 + 240 + 15 = 6553510FFFF可以看作是 0x10FFFF = 1 × 16⁵ + 0 × 16⁴ + 15 × 16³ + 15 × 16² + 15 × 16 + 15 = 1048576 + 0 + 61440 + 3840 + 240 + 15 = 1114111
2.2 规则说明 #
首字节标识:通过首字节的前几位判断字节数
0xxxxxxx:1字节(ASCII)110xxxxx:2字节的首字节1110xxxx:3字节的首字节11110xxx:4字节的首字节
后续字节标识:所有后续字节都以
10开头- 这样可以区分首字节和后续字节
数据位填充:
x表示实际数据位- 将 Unicode 码点的二进制从低位到高位依次填入
2.3 算法实现 #
2.3.1 方法1:Python 内置方法(最简单) #
# 1.获取 Unicode 码点
码点 = ord('中')
print(f'U+{码点:04X}') # U+4E2D
print(码点) # 20013
# 2.从码点创建字符
字符 = chr(0x4E2D)
print(字符) # '中'
# 3.Unicode 字符 → UTF-8 字节
utf8_bytes = '中'.encode('utf-8')
print(utf8_bytes) # b'\xe4\xb8\xad'
print(utf8_bytes.hex()) # 'e4b8ad'
# 4.UTF-8 字节 → Unicode 字符
原字符 = utf8_bytes.decode('utf-8')
print(原字符) # '中'2.3.2 方法2:实现原理 #
# 定义函数,将Unicode码点转为UTF-8字节序列
def unicode_to_utf8(codepoint):
"""
将 Unicode 码点转换为 UTF-8 字节序列
参数:
codepoint: Unicode 码点(整数)
返回:
bytes: UTF-8 编码的字节序列
"""
# 检查码点是否在有效范围内
if codepoint < 0 or codepoint > 0x10FFFF:
raise ValueError(f"无效的 Unicode 码点: {codepoint}")
# 如果码点小于等于0x7F,用1字节表示(ASCII)
if codepoint <= 0x7F:
# 构造单字节
return bytes([codepoint])
# 如果码点小于等于0x7FF,用2字节表示
elif codepoint <= 0x7FF:
# 构造第1字节(110xxxxx)
byte1 = 0b11000000 | (codepoint >> 6)
# 构造第2字节(10xxxxxx)
byte2 = 0b10000000 | (codepoint & 0b00111111)
# 返回组合后的2字节
return bytes([byte1, byte2])
# 如果码点小于等于0xFFFF,用3字节表示
elif codepoint <= 0xFFFF:
# 构造第1字节(1110xxxx)
byte1 = 0b11100000 | (codepoint >> 12)
# 构造第2字节(10xxxxxx)
byte2 = 0b10000000 | ((codepoint >> 6) & 0b00111111)
# 构造第3字节(10xxxxxx)
byte3 = 0b10000000 | (codepoint & 0b00111111)
# 返回组合后的3字节
return bytes([byte1, byte2, byte3])
# 其它情况,用4字节表示
else:
# 构造第1字节(11110xxx)
byte1 = 0b11110000 | (codepoint >> 18)
# 构造第2字节(10xxxxxx)
byte2 = 0b10000000 | ((codepoint >> 12) & 0b00111111)
# 构造第3字节(10xxxxxx)
byte3 = 0b10000000 | ((codepoint >> 6) & 0b00111111)
# 构造第4字节(10xxxxxx)
byte4 = 0b10000000 | (codepoint & 0b00111111)
# 返回组合后的4字节
return bytes([byte1, byte2, byte3, byte4])
# 定义函数,将UTF-8字节序列转换为Unicode码点
def utf8_to_unicode(utf8_bytes):
"""
将 UTF-8 字节序列转换为 Unicode 码点(反向转换)
参数:
utf8_bytes: UTF-8 编码的字节序列
返回:
int: Unicode 码点
"""
# 检查输入是否为空
if not utf8_bytes:
raise ValueError("空字节序列")
# 获取首字节
first_byte = utf8_bytes[0]
# 1字节编码情况:0xxxxxxx
if (first_byte & 0b10000000) == 0:
return first_byte
# 2字节编码情况:110xxxxx 10xxxxxx
elif (first_byte & 0b11100000) == 0b11000000:
# 检查字节长度是否充足
if len(utf8_bytes) < 2:
raise ValueError("不完整的 UTF-8 序列")
# 取高5位+低6位,拼出码点
codepoint = ((first_byte & 0b00011111) << 6) | \
(utf8_bytes[1] & 0b00111111)
return codepoint
# 3字节编码情况:1110xxxx 10xxxxxx 10xxxxxx
elif (first_byte & 0b11110000) == 0b11100000:
# 检查字节长度是否充足
if len(utf8_bytes) < 3:
raise ValueError("不完整的 UTF-8 序列")
# 拼接高4位、中间6位和低6位得码点
codepoint = ((first_byte & 0b00001111) << 12) | \
((utf8_bytes[1] & 0b00111111) << 6) | \
(utf8_bytes[2] & 0b00111111)
return codepoint
# 4字节编码情况:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
elif (first_byte & 0b11111000) == 0b11110000:
# 检查字节长度是否充足
if len(utf8_bytes) < 4:
raise ValueError("不完整的 UTF-8 序列")
# 拼接高3位、次高6位、次低6位和低6位得码点
codepoint = ((first_byte & 0b00000111) << 18) | \
((utf8_bytes[1] & 0b00111111) << 12) | \
((utf8_bytes[2] & 0b00111111) << 6) | \
(utf8_bytes[3] & 0b00111111)
return codepoint
# 非法的UTF-8首字节
else:
raise ValueError("无效的 UTF-8 首字节")
# 测试代码:定义要测试的字符列表
test_chars = ['A', '中', '😀']
# 遍历每个字符
for char in test_chars:
# 取出字符对应的Unicode码点
codepoint = ord(char)
# 手动将码点转为UTF-8字节序列
utf8_manual = unicode_to_utf8(codepoint)
# 用Python内置方法编码
utf8_builtin = char.encode('utf-8')
# 打印字符及转码信息
print(f"\n字符: '{char}'")
print(f" Unicode码点: U+{codepoint:04X} ({codepoint})")
print(f" UTF-8字节: {utf8_manual.hex().upper()}")
print(f" 字节数: {len(utf8_manual)}")
print(f" 验证: {'正确' if utf8_manual == utf8_builtin else '错误'}")
# 用自定义方法解码回码点
decoded = utf8_to_unicode(utf8_manual)
# 再转回字符
decoded_char = chr(decoded)
print(f" 反向解码: '{decoded_char}' (U+{decoded:04X})")3.详细实例 #
3.1 实例1:ASCII字符 'A'(1字节) #
步骤分解:
1️⃣ Unicode 码点
'A' = U+0041 = 65
2️⃣ 判断字节数
65 ≤ 127,使用 1字节编码
3️⃣ 二进制表示
65 = 0100 0001 (8位)
4️⃣ 应用编码格式
格式:0xxxxxxx
填充:0[1000001]
5️⃣ 结果
字节1: 01000001 = 0x41
最终结果: 'A' → 413.2 实例2:汉字 '中'(3字节) #
步骤分解:
1️⃣ Unicode 码点
'中' = U+4E2D = 20013
2️⃣ 判断字节数
2048 ≤ 20013 ≤ 65535,使用 3字节编码
3️⃣ 二进制表示(16位)
0x4E2D = 0100 1110 0010 1101
↓ ↓ ↓ ↓
分组:0100 | 111000 | 101101
高4位 中6位 低6位
4️⃣ 应用编码格式
格式:1110xxxx 10xxxxxx 10xxxxxx
字节1: 1110[0100] = 11100100 = 0xE4
字节2: 10[111000] = 10111000 = 0xB8
字节3: 10[101101] = 10101101 = 0xAD
5️⃣ 位运算实现
高4位 = (0x4E2D >> 12) & 0xF = 0x4
中6位 = (0x4E2D >> 6) & 0x3F = 0x38
低6位 = 0x4E2D & 0x3F = 0x2D
字节1 = 0b11100000 | 0x4 = 0xE4
字节2 = 0b10000000 | 0x38 = 0xB8
字节3 = 0b10000000 | 0x2D = 0xAD
最终结果: '中' → E4 B8 AD3.3 实例3:Emoji '😀'(4字节) #
步骤分解:
1️⃣ Unicode 码点
'😀' = U+1F600 = 128512
2️⃣ 判断字节数
128512 > 65535,使用 4字节编码
3️⃣ 二进制表示(21位)
0x1F600 = 0001 1111 0110 0000 0000
↓ ↓ ↓ ↓ ↓
分组:000 | 011111 | 011000 | 000000
高3位 次高6位 次低6位 低6位
4️⃣ 应用编码格式
格式:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
字节1: 11110[000] = 11110000 = 0xF0
字节2: 10[011111] = 10011111 = 0x9F
字节3: 10[011000] = 10011000 = 0x98
字节4: 10[000000] = 10000000 = 0x80
5️⃣ 位运算实现
高3位 = (0x1F600 >> 18) & 0x7 = 0x0
次高6位 = (0x1F600 >> 12) & 0x3F = 0x1F
次低6位 = (0x1F600 >> 6) & 0x3F = 0x18
低6位 = 0x1F600 & 0x3F = 0x0
字节1 = 0b11110000 | 0x0 = 0xF0
字节2 = 0b10000000 | 0x1F = 0x9F
字节3 = 0b10000000 | 0x18 = 0x98
字节4 = 0b10000000 | 0x0 = 0x80
最终结果: '😀' → F0 9F 98 804.位运算 #
4.1 关键运算符 #
| 运算符 | 说明 | 示例 | ||
|---|---|---|---|---|
>> |
右移(取高位) | 0x4E2D >> 12 = 0x4 |
||
<< |
左移(放大) | 0x4 << 12 = 0x4000 |
||
& |
按位与(提取) | 0x4E2D & 0x3F = 0x2D |
||
| `\ | ` | 按位或(组合) | `0xE0 \ | 0x4=0xE4` |
4.2 常用掩码 #
# 提取位的掩码
0b00111111 = 0x3F # 提取低6位
0b00011111 = 0x1F # 提取低5位
0b00001111 = 0x0F # 提取低4位
0b00000111 = 0x07 # 提取低3位
# 标识位前缀
0b10000000 = 0x80 # 后续字节前缀
0b11000000 = 0xC0 # 2字节首字节前缀
0b11100000 = 0xE0 # 3字节首字节前缀
0b11110000 = 0xF0 # 4字节首字节前缀4.3 位运算示例 #
# 示例:处理 '中' (U+4E2D)
codepoint = 0x4E2D # 20013
# 提取各部分(3字节编码)
高4位 = (codepoint >> 12) & 0x0F # 右移12位,取低4位 → 0x4
中6位 = (codepoint >> 6) & 0x3F # 右移6位,取低6位 → 0x38
低6位 = codepoint & 0x3F # 直接取低6位 → 0x2D
# 组装 UTF-8 字节
字节1 = 0b11100000 | 高4位 # 0xE0 | 0x4 = 0xE4
字节2 = 0b10000000 | 中6位 # 0x80 | 0x38 = 0xB8
字节3 = 0b10000000 | 低6位 # 0x80 | 0x2D = 0xAD
print(f"{字节1:02X} {字节2:02X} {字节3:02X}") # E4 B8 AD5. 总结 #
- Unicode 定义字符编号,UTF-8 定义存储方式
- UTF-8 是变长编码(1-4字节)
- 根据码点范围选择字节数
- 首字节和后续字节有固定的标识位
- 使用位运算提取和组合数据位
- Python 内置
encode()/decode()方法最简单